Domain Adaptation for Gravitational Lens finding| GSOC 22' @ ML4Sci

In this article, I’d like to share my GSOC experience and the lessons I learned. The learning journey with my mentors at ML4Sci was one of the best I’ve ever had; along with Machine Learning, Open-source and Astronomy, I learned a lot. In this project, we used unsupervised domain adaptation techniques and various types of neural networks to detect strong lensing.
Project Overview
The project is part of the DeepLense pipeline, which utilises state-of-the-art deep learning techniques in the search for dark matter via strong gravitational lensing. Gravitational Lensing is the phenomenon in which the gravitational influence of a galaxy (or another large celestial object) bends the light of the galaxy behind it, resulting in different shapes and substructures such as arcs and halos.

Detecting lensing in images will allow these images to be passed on to the DeepLense project’s other stages for detection, classification, and interpretation of dark matter substructure. Because proper processing of images from telescopes and finding real strong lensed images are difficult, most projects in this domain rely on simulated data. As a result, we will attempt to transfer what a deep learning model has learned from a dataset of simulated images to a set of real images. Real data will be our ‘target’ dataset in this context, whereas simulated data, which will be labelled, will be our source data. I initially intended to use classification ideas in the project, but after a few tries, the results were becoming stagnant, and we were unable to improve upon them. After reading numerous papers, we were finally inspired by the Domain adaptation results presented in this paper (https://arxiv.org/abs/2112.12121), and we began to consider conducting experiments on our task. Domain Adaptation techniques help us to transfer the knowledge from source data to target data.
About Me
I am Mriganka Nath, I have recently completed my bachelor's in Electronics and Communication Engg from NIT Silchar, India. I enjoy learning Machine Learning and thinking of ways to tackle data-related problems.
This project sparked my interest because it would require me to learn and implement new things. I had previously participated in the ML4SCI hackathon and earned a rank, which increased my desire to work with astronomical data. As a result, I was eager to contribute to this project.
The code
The code along with tutorial notebooks and how-tos is provided here (https://github.com/ML4SCI/DeepLense/tree/main/DeepLense_Gravitational_Lensing_Mriganka_Nath). I have used kaggle notebooks to train the models, so if you try to run on Colab there can be some dependency or version errors, so I recommend using kaggle, else you can install the required libraries from requirements.txt.
Dataset
As discussed above, we will work with the source and target datasets. We will be using two datasets, simulated and real. The real data is obtained from Hyper Suprime-Cam (HSC) Subaru Strategic Program Public Data Release 2. ( The HSC website https://hsc-release.mtk.nao.ac.jp/doc/index.php/sample-page/pdr2/) There are almost 40k images here with 400 being the number of lense candidates. Simulated data made using lenstronomy code. There is a total of ~ 60k images, with 20k being lens candidates and the rest being non-lensed.
For source data, we used simulated data which was a bit skewed. Label ‘0’ is used for non-lensed images and ‘1’ for lensed ones.

The real data is very much skewed.
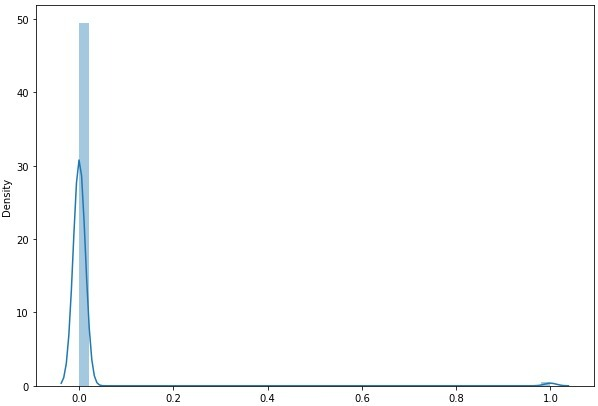
For testing, we used 20 % of the real dataset (94 are lensed and 8000 are non-lensed). We used stratified splitting to preserve the distribution of the real dataset in the test data.
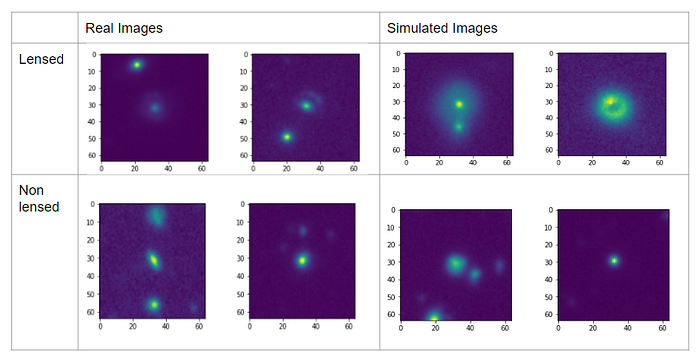
Preprocessing of data
For the preprocessing of data, we made the values range from 0 to 1. By using this formula
X_scaled = (X - X.min) / (X.max - X.min)
Where X is the image containing pixels of differnt values, X.min is the least value of the pixel wheras X.max is the largest.We also tried adding log transformation, but it didn't help much. We experimented with different types of Augmentation. For augmentations, we used the Albumentations library. We were cautious about adding more augmentations because it may add more noise to the signal, which might make the model more confused. Some of the augmentations we used are (although it may vary from model to model, to see exact augmentations, look at the notebooks)
- Random Cropping
- Horizontal
- Vertical Flip
- Gaussian Noise
Unsupervised Domain Adaptation
UDA is the task of making a model learn from a source dataset which is labelled and transfer what it has learned to a target dataset, which is unlabelled. The constraint is here both datasets are used to solve the same objective. Here simulated data is the source data whereas the real data was the target data.
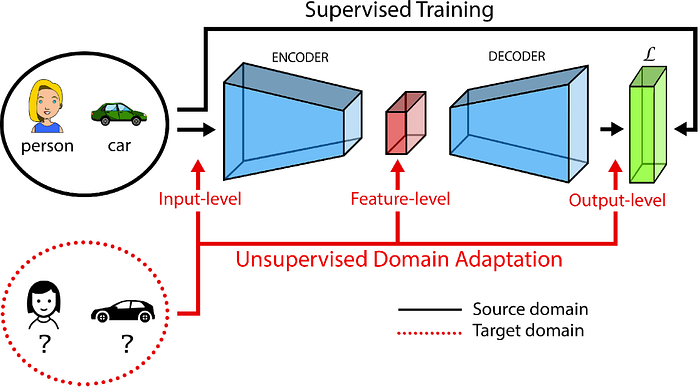
ADDA(Adversarial Discriminative Domain Adaptation)
ADDA by Eric Tzeng, Judy Hoffman, Kate Saenko, Trevor Darrell (https://arxiv.org/pdf/1702.05464.pdf)is an adversarial domain adaptation method, where the first objective is to minimize the domain discrepancy with an adversarial loss and then to classify the images properly. Here we are fooling the Discriminator to make it unable to classify between real and simulated images (adversarial step). That would make the model think images from both the domains are the same, and after this step, we can use previous models that were used to classify them into lensed or non-lensed (pretraining step). In practice, the pretraining step happens first and then adversarial.
Data preparation
# source data
X_train, X_val , X_test = prep_data(cls1 , cls2) # splits the dataset#Target data is stored in a csv
df= pd.read_csv("real_data.csv")# Image Augmentations using Albumentations
image_size = 64
train_aug = A.Compose(
[
A.RandomCrop(32,32,p=0.5),
A.HorizontalFlip(p=0.25),
A.VerticalFlip(p=0.25),
A.Resize(image_size,image_size,p=1.0),
ToTensorV2()
]
)
val_aug = A.Compose(
[
A.Resize(image_size,image_size,p=1.0),
ToTensorV2()
]
)#Dataset class
s_data = Discriminator_dataset(X_train , train_aug)
t_data = Discriminator_dataset(df.values , train_aug,source = False)# Dataloaders
s_loader = DataLoader(s_data, shuffle=True,
num_workers=4,
batch_size=100,drop_last = True)
t_loader = DataLoader(t_data, shuffle=True,
num_workers=4,
batch_size=100,drop_last =True)
Model
We can use a range of pretrained models to experiment, to know what pretrained models could be used, and use
available_backbone_models()But we have used Equivariant CNN, so we will use
# make sure device is declared
s_encoder = ECNN()
s_encoder = s_encoder.to(device)
t_encoder = ECNN()
t_encoder = t_encoder.to(device)
classifier = Classifier()
classifier = classifier.to(device)
discriminator = Discriminator()
discriminator = discriminator.to(device)Hyperparameters
We can load the required hyperparameters using this
hpms = ADDA_HPAMS()Training
adda_train = ADDA_Train(s_loader,t_loader ,tv_loader, s_encoder , t_encoder , discriminator,classifier,adda_hpms,OUTPUT_DIR,device)adda_train.train()
Test results
https://github.com/mrinath123/Deeplense_Gravitational_lensing/blob/main/notebooks/adda-ecnn.ipynb to know the full training process.
Self Ensembling
Self-Ensemble (from “Self-ensembling for visual domain adaptation” by Geoffrey French, Michal Mackiewicz, Mark Fisher) is based on student-teacher networks used in semi-supervised methods.
The full training process is discussed here https://github.com/mrinath123/Deeplense_Gravitational_lensing/blob/main/notebooks/self-ensembling-effnet.ipynb
Test results
AdaMatch
AdaMatch (from “AdaMatch: A Unified Approach to Semi-Supervised Learning and Domain Adaptation” by David Berthelot, Rebecca Roelofs, Kihyuk Sohn, Nicholas Carlini, Alex Kurakin) is a technique that unifies UDA with semi-supervised learning and semi-supervised domain adaptation. Pseudo labels for target images are created during training and another model is used to predict them, and loss calculated.
Test results
The full training process is discussed here https://github.com/mrinath123/Deeplense_Gravitational_lensing/blob/main/notebooks/adamatch-effnet.ipynb
Observations and Results
We have experimented with different encoder architectures for each model like efficeintnet_b2, resnet34, densenet121 and equivariant convolutional neural networks. Here in the table, we show the test aucroc score for each of them.
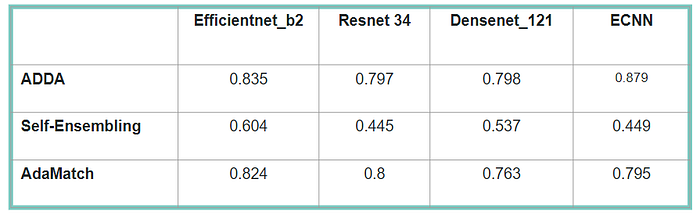
The baseline aucroc score, that is, the test aucroc score when using simple classification that is trained on source data and tested on target data, is 0.816. UDA outperforms this score! so we can say it is beneficial in our case.
We discovered that the same hyperparameters do not work for each technique, even if the encoder is the same. The type of augmentations and data preprocessing had a big impact on the training.
Future work & Takeaways
This project demonstrated that domain adaptation outperforms basic classification, but we believe there are many areas where we can improve. We expect that the better the simulated data and how well it represents the real data, the better the performance. Currently, our simulations differ from the real data in terms of brightness and size. Also in our experiments, we discovered that having the same imbalance in real and simulated data helps with training.
We also intend to investigate why some encoders perform better than others; on average. We will attempt to create Grad-CAM or investigate the features learned by the models. We’ve seen experiments (https://github.com/ML4SCI/DeepLense/tree/main/Transformers_Classification_DeepLense_Kartik_Sachdev) where vision transformers perform exceptionally well with dark matter substructure classification; we could test them and see how they perform. Also, because UDA methods are extremely sensitive to hyperparameters, a more extensive search for hyperparameters may be required for improved performance. Even though it is computationally expensive, we can get the best results from our models if we have access to appropriate hardware.
Finally, I would like to express my gratitude to my mentors, Sourav Raha, Michael Toomey, Sergei Gleyzer, and especially Anna Parul for helping me out with the datasets. I am fortunate to work with them. I’ve learned a lot from this project, including how to maintain an entire open-source project with code and documentation while reading numerous research papers on domain adaptation. In addition, I want to thank the GSOC programme for providing me with this wonderful opportunity.
